How we turned 5,825 parliamentary recommendations into a searchable thread map


Carl is a data lead at OpenUp. He is passionate about turning information into data.
Each year, Parliament's committees publish dense PDF reports. We extracted recommendations by hand, then used an LLM to scale – so anyone can track which "asks" were repeated.
If a parliamentary portfolio committee tells a department and its entities to fix something, and the department doesn't fix it, what happens? Often, the committee tells them again the next year. And the year after that. Sometimes for half a decade.
This pattern of repetition is one of the most useful signals in South African oversight: It tells you what's stuck, what's being ignored, and where Parliament's recommendations have actually moved the needle. The problem is that the signal is buried inside hundreds of Budget Review and Recommendations Reports (BRRRs) – each one a long, idiosyncratic PDF written by the respective portfolio committee.
It tells you what's stuck, what's being ignored, and where Parliament's recommendations have actually moved the needle.
To make that signal visible, we built a three-stage pipeline:
- Hand-extract a ground-truth corpus of recommendations from BRRRs into spreadsheets, defining the schema and decision rules that the rest of the pipeline inherits;
- Use an LLM (in our case, Claude) to extract recommendations from raw PDF text into structured rows; and
- Match those rows across years into threads, with each thread tracing one recommendation as it persists, evolves, or finally lands.
The result is now live in the form of the BRRR dashboard on ParliMeter.
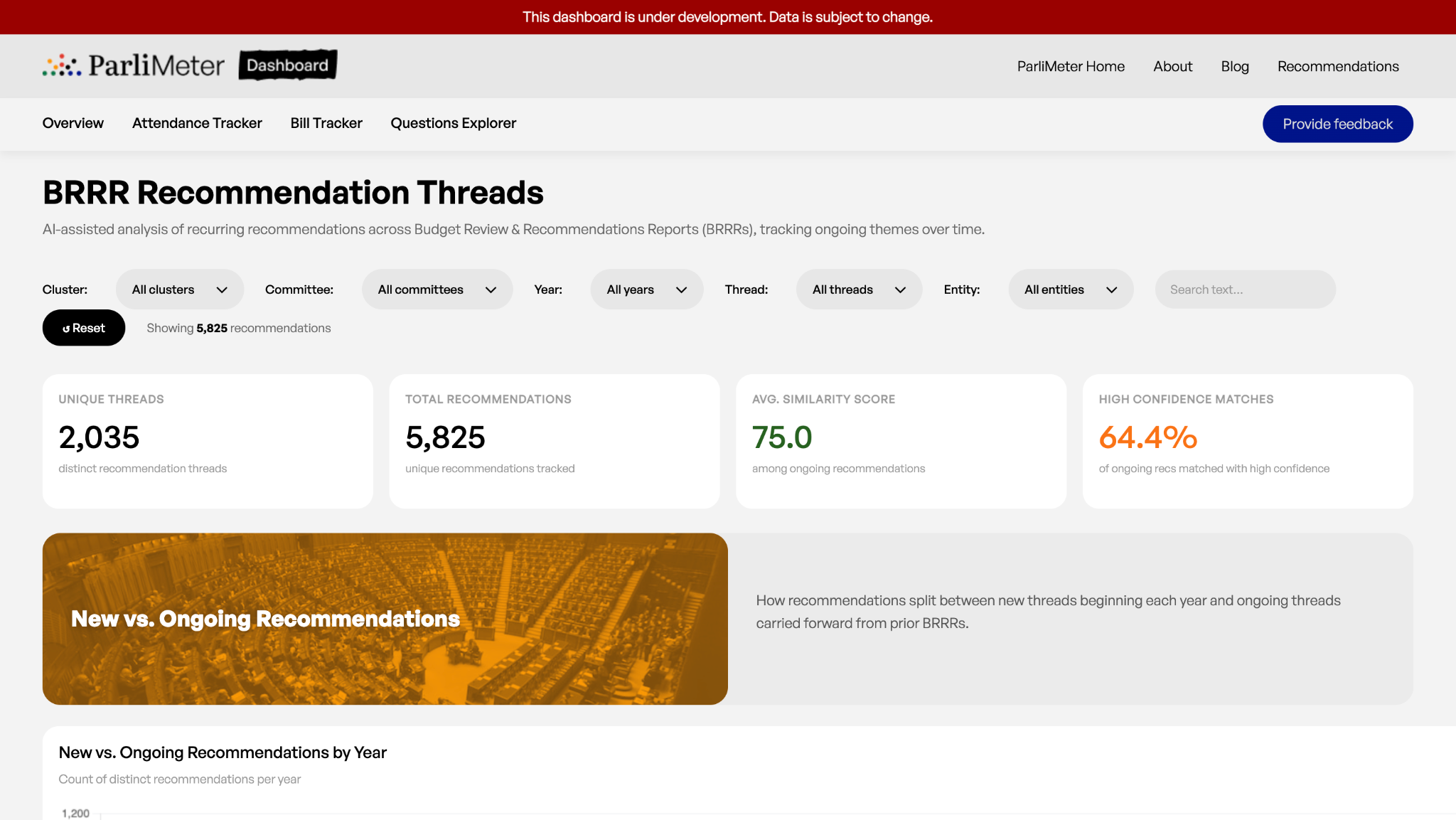
This blog will give you, the user, more insight into the methodology behind the dashboard. It's a story about prompt design, the messy reality of PDFs, the small decisions that determine whether an LLM produces useful, structured data or just expensive nonsense, and the human judgement that has to come first.
Why this matters
BRRRs are how Parliament tells the executive what to do better. Each portfolio committee (for example, Health, Police, Cooperative Governance, Transport, and so on) produces an annual BRRR after reviewing a department's budget and annual performance. Tucked inside is a section of recommendations such as “fill these vacancies”, “account for that irregular expenditure”, or “brief us on this implementation plan by the next quarter”.
Any one BRRR is readable. The full corpus is not. Across roughly 30 portfolio committees, one standing committee and seven years, you get thousands of recommendations spread across hundreds of PDFs, with no shared schema, no recommendation IDs, and no consistent way of saying: “We asked you about this last year too.”
Any one BRRR is readable. The full corpus is not.
Without structure, you cannot ask the most basic oversight questions, such as:
- Which recommendations have been repeated for years without resolution?
- Which departments accumulate the most repeat asks?
- When a committee changes (or merges, or splits), do the threads survive the handover?
Our job was to turn the corpus into something where those questions have answers.
What BRRR documents are, and why they're hard
Anyone who has tried to extract data from a government PDF knows the genre. Tables that aren't tables. Footnotes mid-sentence. Bullet points that switch from dots, to dashes, to numbers, to letters across a single document. Section headings that imply which department a block of recommendations belongs to without ever naming it inline. Page breaks splitting a single recommendation across two pages, with a header and a footer in the middle.
And these are good documents! They're public, well-archived, and carefully written. The mess is just the natural texture of long-form government writing, rendered through a layout engine. An LLM is well-suited to reading through that texture, but only if you tell it precisely what to keep, what to throw away, and how to label what it keeps.
An LLM is well-suited to reading through that texture, but only if you tell it precisely what to keep, what to throw away, and how to label what it keeps.
The three-stage pipeline, end to end

Stage 1: The manual work that made it possible
Before any prompt was written or any model was called, our colleague, Naailah Parbhoo from the Organisation for Undoing Tax Abuse (OUTA), spent months reading BRRRs by hand. She opened each PDF, found the recommendations section, and copied every recommendation, line by line, into Excel, alongside the committee, the year and the department or institution being asked to act. It's slow, careful, attentive work, and it is the reason the rest of this pipeline exists.
“The process began with downloading the BRRR reports from [the Parliamentary Monitoring Group] PMG’s website, identifying the recommendation sections and extracting each recommendation into an Excel spreadsheet,” says Parbhoo. “Search terms, categories and Indicators for Democratic Parliaments were assigned, before each recommendation was checked to determine whether it was new, repeated or ongoing between 2019 and 2025.”
...each recommendation was checked to determine whether it was new, repeated or ongoing between 2019 and 2025.
That manual corpus does two things for us that the LLM, on its own, could never have done:
It defines what a "recommendation" actually is.
BRRRs do not label their recommendations consistently. Some are bulleted, some are buried in paragraphs, some live under headings called “Findings” or “Observations” that read like recommendations in everything but name. Parbhoo's spreadsheets were the working answer to: “What counts as a recommendation?”. This is a question we never had to re-litigate when we sat down to write the extraction prompt.
It taught us the texture of the documents.
The square-bracket trick for inferred departments, the wide-net entity extraction, the verbatim rule – none of those design choices came out of thin air. They came from sitting with Parbhoo’s Excel files and asking: “What did she have to do that the model will also need to do?”. The prompts are, in a real sense, an attempt to encode her judgement at scale.
The scale of the extraction work is also the reason why we eventually moved to an LLM. While Parbhoo’s manual extraction covered the full corpus, assigning unique IDs and matching threads across so many recommendations by hand would have taken many more months than the project had.
The LLM pipeline is a force multiplier on human work, not a replacement for it.
We also use the manual spreadsheets as a ground-truth check. Where Parbhoo’s extractions and the LLM's extractions cover the same committee-year, we can spot-compare them: Rows the model missed, rows it split or merged differently, and entities it tagged differently. Those comparisons are how we fine tuned the prompts and how we know, with some confidence, when the pipeline is producing useful structured data rather than expensive nonsense.
So, when you read the rest of this post and see the pipeline described in terms of two prompts and a model, keep the earlier layer in mind. The prompts are only as good as the judgement encoded in them, and that judgement was built, recommendation by recommendation, in a spreadsheet – long before any of this was automated.
Stage 2: Extracting recommendations
Stage 2 is structured extraction. We paste a chunk of recommendation text from a BRRR PDF into a prompt, alongside three pieces of metadata: The committee's full name, its acronym, and the year. The model returns a Markdown table (one row per recommendation) with six columns: A unique ID, the three metadata fields, the recommendation's raw_text, and a list of entities_mentioned.
Two design choices in this prompt do most of the heavy lifting:
1. raw_text is preserved verbatim
The model is explicitly told not to clean up typos, fix punctuation, or paraphrase. If a sentence has a spelling error or a stray bullet, that artefact stays. This may sound counterintuitive – surely, cleaner text is better, right? But the verbatim rule is what makes Stage 3 work. Semantic similarity scoring across years is fragile. If the model summarises one year and quotes another, two identical recommendations look like two different ones. The verbatim rule is the contract that keeps similarity meaningful downstream, and comes directly from the manual extraction protocol.
2. Entities are extracted with a wide net
The prompt walks the model through six categories of named entities (departments, named officials, legislation, programmes, institutions, and named places) and asks it to extract everything with a proper name. For example, "AGSA", "Section 139 of the Constitution", "Mangaung Metro" or "Municipal Infrastructure Grant" are all included. Generic references like "the department" or "the Committee" are excluded.
The reason for casting wide is that in Stage 3, a shared entity is a hard gate for matching two recommendations as the same thread. If we under-extract entities here, we systematically miss matches there. So, we err on the side of inclusion, but we do so transparently.
3. The square-bracket trick
Parliamentary PDFs frequently group recommendations under a section heading like "Department of Water and Sanitation", then never repeat the department's name in any individual recommendation under that heading. To a naive extractor, those recommendations look department-less. Our prompt handles this by inferring the entity from context, and then tagging it inside the raw_text with square brackets, like [Department of Water and Sanitation], so a human reviewer can always see which entities were inferred from structure, rather than stated outright. The audit trail and signal remain preserved.

Stage 3: Matching recommendations across years
Stage 3 is where the threads form. Once we have clean rows for every committee and every year, we run them through a second prompt that processes one year at a time, in chronological order, comparing each new year's rows against a cumulative baseline of all prior years.
For each new recommendation, the model picks one of four classifications:
- Persisting: Substantively unchanged from a prior year. Inherits that thread.
- Modified: Same theme, but scope, target, or framing has shifted. Inherits that thread.
- New: No meaningful overlap with anything before it. Starts a new thread.
- Uncertain: There's a thematic link, but the match isn't confident enough to commit. Starts a new thread, and is flagged.
The trick (and the reason this prompt is much longer than in Stage 2) is that “the same recommendation” is genuinely hard to pin down. Two rows can read almost identically and mean different things. Two rows can read very differently and mean the same thing.
The trick [...] is that “the same recommendation” is genuinely hard to pin down.
So, we decompose intent into three components that the model has to reason about explicitly, which mirrors how Parbhoo was already grouping rows in Excel:
- Action: What is being requested? For example, “submit a report”, “fill vacancies”, or “brief the committee”.
- Subject: What the action concerns? For example, “irregular expenditure”, “vacancy rate”, or “audit action plan”.
- Target: Who is being asked to act? For example, “the Department”, “AGSA”, or “National Treasury”.
If all three match, it's Persisting. If the subject matches but the action or scope has changed, it's Modified. If the subject itself has shifted, it's probably New. And on top of that, at least one named entity must be shared! Semantic similarity alone, without a shared institutional anchor, is never enough to call something a match.
That entity gate is the single most important guardrail in the whole pipeline. Boilerplate parliamentary phrasing is everywhere. A phrase like “...the Department should submit a report to the Committee…” can appear in dozens of unrelated recommendations. Without an entity in common, “looks similar” is just noise.

Prompt design choices and tradeoffs
Here are a few of the decisions that we agonised over, and what we settled on:
Prefer Uncertain over False Positive
The four-class system exists because a binary “match / no match” forces the model to overcommit. Uncertain is a deliberate escape valve: When a thematic link exists but the entity gate fails, or if confidence in the directional match is low, the row gets a fresh thread and a note explaining why. The downstream effect is that a small amount of threads will be slightly fragmented, but the alternative – fabricated continuity – is much worse for an oversight tool.
Frozen baseline rows
Once a row is classified, we never re-classify it in a later round. The baseline is append-only. This costs us some theoretical accuracy (for example, a 2024 recommendation might reveal that a 2021 classification was wrong), but it gives us something more important: A stable audit trail. A user can always click into a thread and see the chain of decisions that produced it, in order, without worrying that yesterday's view will contradict today's.
Cumulative baseline, not just last year
Each round compares the current year against all previously processed years, not just the most recent. This handles the common occurrence where a recommendation disappears for a year and then comes back. Without it, the returning row would be misclassified as New and the thread would be broken.
Two-class user view, four-class internal model
Internally, we keep all four classes. On the dashboard, we collapse them to New and Ongoing, because for a journalist or a curious citizen, "Is this a fresh ask or a repeat?" is the question that matters. Modified, Persisting and Uncertain rows all fall under Ongoing in the headline view, but the underlying classification is one click away for anyone who wants more detail.
It is not as simple as plug and play. But when you get the structure right, an LLM can do something a small civic-tech team genuinely couldn't do otherwise: Read every recommendation Parliament has made for seven years, and tell you which ones are still on the table.
What this gets us
“The dashboard makes BRRR recommendations easier to find, track and compare across years and committees,” says Parbhoo. “It can help civil society organisations, researchers, parliamentarians and the public to monitor whether departments are implementing recommendations and hold them to account when they don’t.”
Of the 5,825 recommendations we processed, about 65% are part of an ongoing thread (i.e. they have a recognisable predecessor in a prior year). That, on its own, is a finding: Most parliamentary recommendations are not one-off asks – they are recurring pressures on slow-moving targets. Some threads run unbroken across the full seven years of our dataset.
Of the 5,825 recommendations we processed, about 65% are part of an ongoing thread...
The dashboard lets you filter by committee, by year, by entity, or by individual thread. You can find the longest-running unresolved recommendations, see which committees have the most repeat asks, and read every link in a thread in chronological order. We hope it's useful for journalists looking for accountability stories, for funders evaluating where reform pressure is concentrated, and for committees themselves (who, in some cases, may not realise for how many years they have been asking the same question).
We hope it's useful for journalists looking for accountability stories, for funders evaluating where reform pressure is concentrated, and for committees themselves...
What we'd say to anyone doing this kind of work
The headline lesson, for us, is stated above: Structured LLM extraction is a real superpower, but only when the surrounding scaffolding takes the model's failure modes seriously. The verbatim rule, the wide-net entity extraction, the hard entity gate, the four-class classifier with Uncertain as the safety valve, the frozen baseline – none of these are clever. They are small, careful decisions about what not to let the model do. That is, in our experience, where most of the value lives.
The other, just as important lesson: Do the foundational, manual work first, informed and led by human expertise. Every prompt design choice that worked for us was something a human had already worked out, by hand. The LLM scaled that judgement; it did not invent it.
Every prompt design choice that worked for us was something a human had already worked out, by hand.
The BRRR dashboard is part of ParliMeter. The data is currently in development and subject to change. We'd love your feedback! There's a link on the dashboard, or you can reach us through the ParliMeter site. Full prompts and methodology documents for both stages are available on request.

.jpeg)



Work with us
We are looking for resource and data partners!
If you or your organisation would like to contribute or collaborate, please get in touch.
You might also like

IDP Targets 1 & 2: How can we build a stronger South African Parliament?